Поддержка выгрузки нод alfresco в таблицу базы данных
В микросервисе ecos-integrations добавлена поддержка выгрузки нод альфреско в таблицу базы данных. На данный момент выгрузка осуществляется в таблицы БД микросервиса ecos-integrations.
Команда для подключения к БД на стенде с контейнерами докера:
/usr/bin/psql postgres://integrations@localhost:15432/integrations
Параметры для подключения к alfresco по REST:
ecos-integrations:
alfresco:
url: http://ecos:8080
authentication:
username: integrations
password: 97qiow104UIG
Можно менять эти настройки на стендах или оставить как есть (будет работать только если ECOS развернут в той же докер сети под именем «ecos»).
На стороне alfresco для микросервиса должна быть заведена учетная запись integrations с паролем 97qiow104UIG (значения по-умолчанию) и админскими правами.
Скрипт для создания пользователя:
var userName = "integrations";
people.createPerson(userName, userName, userName, userName + "@ecos.ru", "97qiow104UIG", true);
var adminsGroup = groups.getGroup("ALFRESCO_ADMINISTRATORS");
adminsGroup.addAuthority(userName);
Чтобы настроить выгрузку нод необходимо на стенде с ecos-enterprise-repo модулем открыть системные журналы в alfresco и найти там журнал Синхронизация (Synchronization):
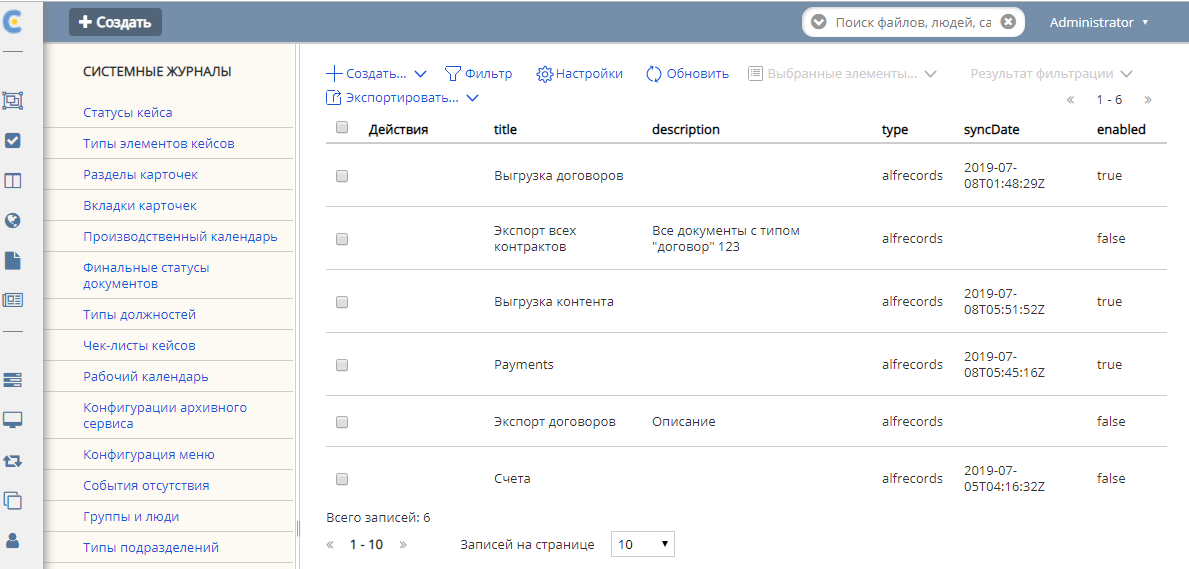
title - заголовок синхронизации
description - описание синхронизации
type - тип синхронизации (пока доступен только 1 тип - alfrescords (выгрузка нод альфреско))
enabled - включена или нет синхронизация
В журнале можно создать новую выгрузку двумя способами:
Создание с помощью полей формы (удобно для создания «с нуля»)
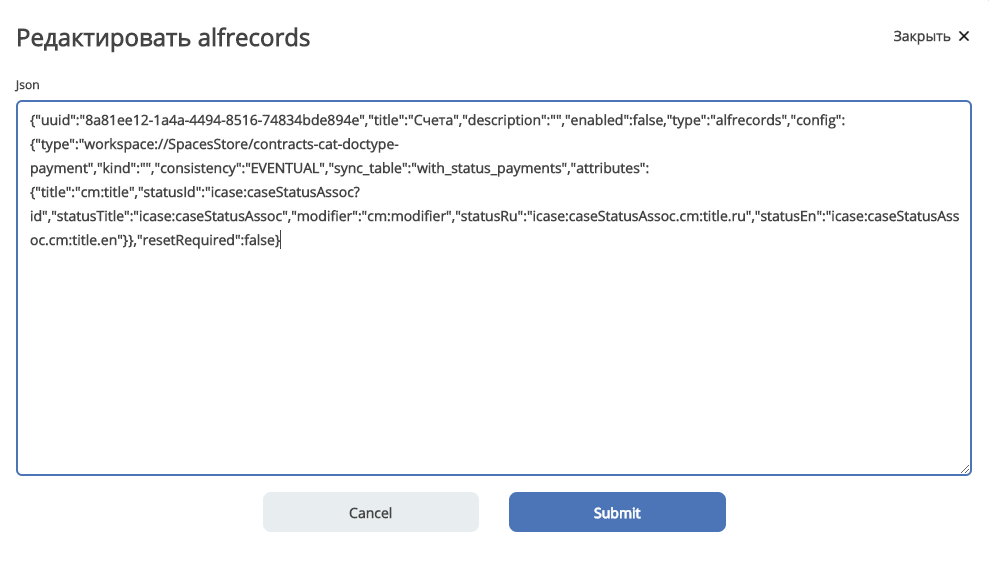
Создание с вводом json (удобно для переноса конфигурации между серверами)
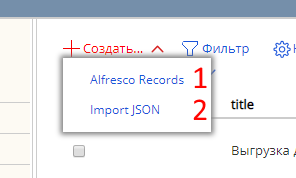
Создание с помощью формы выглядит следующим образом:
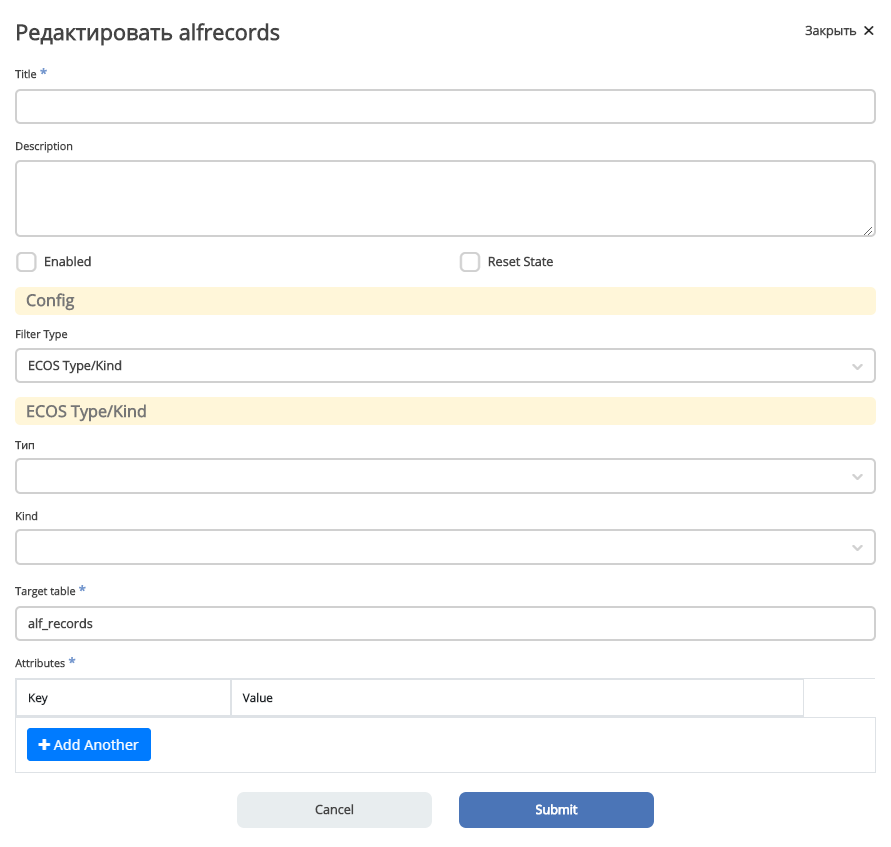
Title - Заголовок выгрузки. Нужен для отображения в журнале синхронизации
Description - Описание выгрузки. Следует заполнить это поле чтобы другие люди могли сразу понять предназначение выгрузки.
Enabled - Включить/выключить синхронизацию;
Reset state - Сбросить состояние (выгрузка начнется с самого начала)
Config - Раздел с конфигурацией выгрузки
- Filter type - Тип фильтра, по которому будут выбираться ноды для выгрузки. На момент написания статьи доступно два типа:
ECOS Type/Kind - фильтрация происходит по выбраному типу и виду
Raw Predicate - фильтрация происходит по заданному предикату в формате JSON. Синтаксис предикатов можно посмотреть Select Journal
Target table - Имя таблицы для выгрузки. В базе данных к этому имени прибавится префикс ecos_sync_ чтобы исключить случайные изменения системных таблиц.
Attributes - Выгружаемые аттрибуты. Слева описываются названия колонок в результирующей таблице, а справа выгружаемые аттрибуты. Синтаксис аттрибутов в правой колонке используется из Records API. Т.о. можно выгружать вложенные аттрибуты.
Например, для выгрузки статуса договора можно описать следующие аттрибуты:
{
"status_id": "icase:caseStatusAssoc?id", //нодреф статуса
"status_ru": "icase:caseStatusAssoc.cm:title.ru", //заголовок статуса на русском
"status_en": "icase:caseStatusAssoc.cm:title.en", //заголовок статуса на английском
}
Если у аттрибута опустить тип скаляра (после знака ?), то по-умолчанию все аттрибуты будут выгружаться в строковом виде. Если требуется числовой вид, то следует добавить к аттрибуту ?num, а для булева поля ?bool.
Для полей с датой на данный момент есть возможность их выгрузить в виде строки с форматом ISO8601 (это происходит автоматически и дополнительной настройки для этого не нужно).
Подробнее о синтаксисе аттрибутов можно почитать в соответствующей статье ECOS Records API
Изменение синхронизации «на лету»
Настройку синхронизации можно менять без перезагрузки сервера. При этом есть несколько особенностей:
Новые аттрибуты будут появляться только для заявок, которые изменились с момента изменения конфигурации. Для того чтобы новые аттрибуты появились у всех записей можно воспользоваться двумя способами:
Первый - сбрасываем состояние синхронизации и недостающие данные синхронизируются полностью.
Второй - создаем новую конфигурацию с недостающими атрибутами(которые были добавлены в исходную конфигурацию) и устанавливаем в ней ту же таблицу что и в исходной конфигурации. Когда новая конфигурации догонит старую, новую можно будет удалить.
При удалении аттрибутов таблица не чистится. То что уже синзронизировано остается в таблице.
Изменение типа колонки на данный момент не поддерживается. Т.о. следует создать новый аттрибут если есть такая необходимость, а старый удалить из конфигурации. Для миграции старых записей можно воспользоваться рекоментациями из п.1
Перенос конфигурации между стендами
Затем нужно:
Скопировать содержимое этого файла
перейти на целевой стенд
открыть журнал синхронизации
Нажать Создать → Import JSON
В появившемся окне вставить json, который мы скопировали в п.1
Сохранить форму
Обновить содержимое журнала
Структура таблицы с данными
id (SERIAL PRIMARY KEY) - идентификатор строки,
_modified (TIMESTAMPTZ) - дата последнего изменения строки,
_created (TIMESTAMPTZ) - дата создания строки,
_version (BIGINT) - внутренняя версия записи. Используется, чтобы избежать одновременного изменения из раных потоков или инстансов микросервиса.
modified (VARCHAR) - дата изменения, записи в alfresco в ISO8601,
record_ref (VARCHAR) - alfresco@ + nodeRef заявки в alfresco
все поля, которые описаны в интерфейсе
Пример скрипта для просмотра существующих записей в alfresco, для просмотра данных которые пойдут в таблицу интеграции
Часть с атрибутами можно взять из json конфигурации интеграции, поле «attributes»:
Citeck.Records.query({
query: 'tk:type:"workspace://SpacesStore/type-te-request"',
language: 'fts-alfresco',
consistency: 'EVENTUAL',
page: {
maxItems: 100
}
}, {
"Reg Number": "uterm:terRegNumber",
"Expense Type": "uterm:terExpenseType.utedm:teetName",
"RP": "uterm:reportablePerson",
"RP Cost Center ": "uterm:terRPCostCenter",
"OS GRC Code": "uterm:terOrdSignCRGCode.cm:title",
"RP Vendor Code": "uterm:terRPVendorCode",
"RP ID": "uterm:terRPPersonnelNumber",
"RP Sub Function": "uterm:terRPSubFunction.udm:subFunctionName",
"AR Approve Date": "uterm:terAdvRepApproveDate",
"OS Date": "uterm:terOrdSignDate",
"Status": "icase:caseStatusAssoc.cm:title",
"Line Manager": "uterm:terLineManager",
"Accountant": "uterm:terAccountant",
"OS Goal Travel": "uterm:terOrdSignGoalTravelType.cm:title",
"OS Outsider Goal Travel": "uterm:terOrdSignOutsiderGoalTravelType.cm:title",
"OS Travel Begin Date": "uterm:terOrdSignTravelBeginDate",
"OS Travel End Date": "uterm:terOrdSignTravelEndDate",
"OS Destination City": "uterm:terOrdSignDestinationCity",
"OS Diff Destination Point": "uterm:terOrdSignDiffDestinationPoint",
"OS Hotel Required": "uterm:terOrdSignHotelRequired.cm:title",
"OS Ticket Required": "uterm:terOrdSignTicketRequired",
"OS Tickets": "uterm:terOrdSignTicketsTable.uterm:tertTransportType",
"AR Doc Requester Amount": "uterm:terAdvRepDocRequesterAmount",
"AR Currency": "uterm:terAdvRepCurrency.idocs:currencyName"
}).then(console.log);
«Reg Number» - key (Attributes), «uterm:terRegNumber» - value (Attributes)
Восстановление потеряных записей
Версия микросервиса: 1.14.0
На форму добавлен флаг “Run recovery job”. Если он активен, то вместе с основной выгрузкой дополнительно запускается джоба, которая ищет пропущенные записи за последний час. Если такие записи находятся, то происходит запуск восстановления. В процессе восстановления сужается диапазон дат, между которыми найдено отличие. После уменьшения диапазона происходит пересинхронизация найденых в нем записией.
Важно
значение флага проверяется только при запуске выгрузки (флаг Enabled переключается с False на True) или при перезагрузке микросервиса.
Дата модификации записи сохраняется в поле _rec_modified. Возможно потребуется создание индексов для этого поля, чтобы джоба работала эффективнее (Но все же если поиск будет долгим, то ничего страшного не произойдет. Просто восстановление будет происходить не так быстро).
Версия микросервиса: 1.18.0
На форму добавлено поле “Recovery job duration (in hours)”, доступно когда установлен флаг “Run recovery job”. Задает время в часах, за которое будет осуществлятся поиск пропущенных записей (по умолчанию 1 час, ограничение на форме от 1 до 12).
На форму добавлено поле “Reset sync date”, не доступно когда установлен флаг “Reset State”. Задает время старта синхронизации, если указанное время больше текущего времени синхронизации у задачи, то данное изменение не применяется.